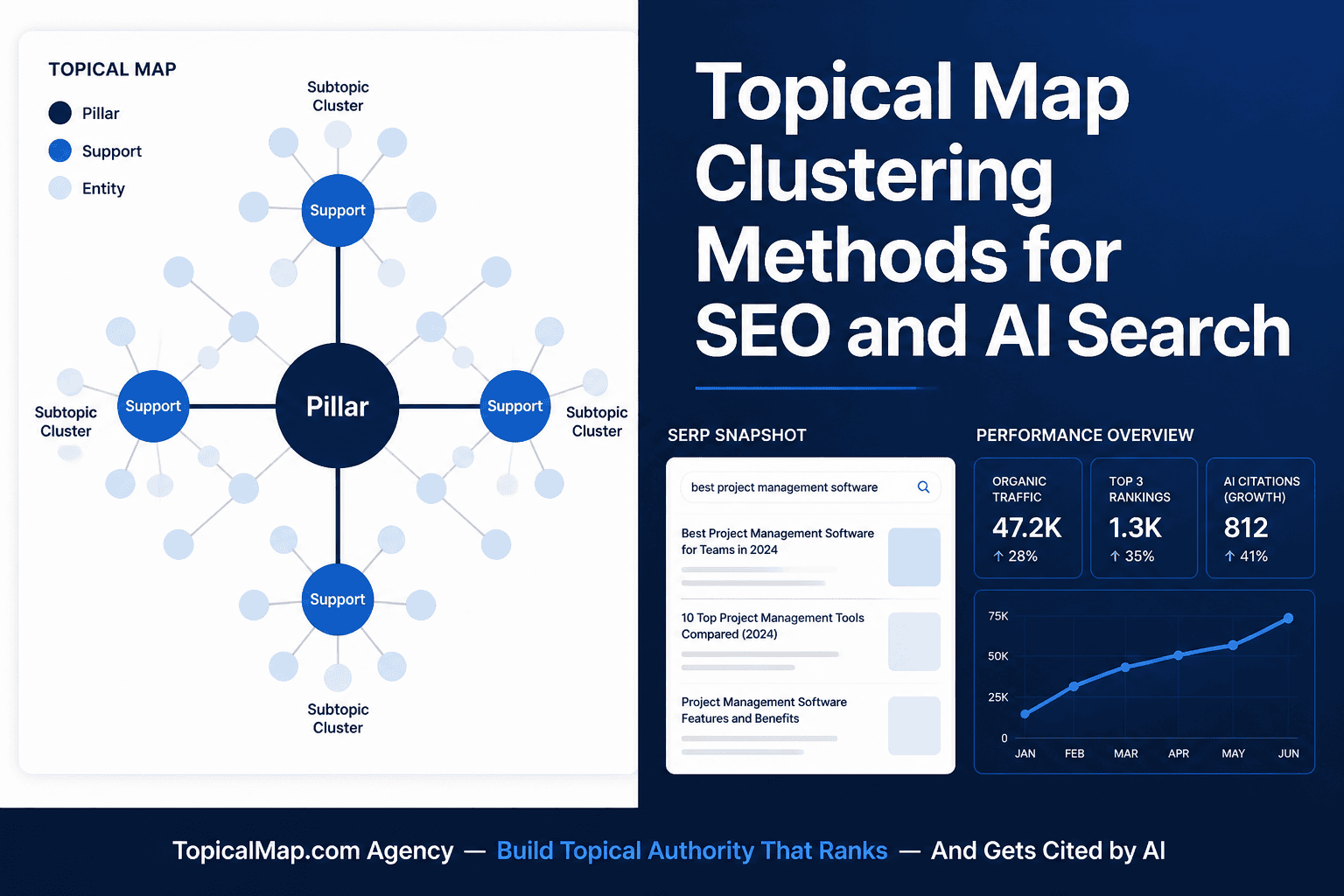
Topical map clustering methods for SEO and AI search help turn keyword lists into site structures that rank and get cited. Many SaaS, e-commerce, and agency teams hit the same friction point when similar terms start competing, search intent splits, and AI systems need clearer relationships to trust. Topical map clustering is the process of grouping related keywords, subtopics, and entities into one site architecture, and the payoff is a cleaner path to coverage, fewer cannibalization risks, and stronger topical authority.
The article compares SERP overlap, semantic embeddings, entity graphs, and hybrid workflows so you can choose the right method for the size and shape of your inventory. It also shows how to build a master sheet, set overlap thresholds, label clusters, and validate the final map for gaps, overlap, and retrieval readiness. Expect practical checkpoints, a simple decision framework, and handoff-ready fields that make the structure easier for writers, strategists, and editors to use.
Heads of content, senior SEO consultants, agency principals, and content team leads will get the most value here because the methods affect research time, page ownership, and internal linking quality. One example is a cluster set that looks separate in a spreadsheet but shares the same top URLs, which is a signal to merge it before publishing. The result is a map that supports SEO performance and gives AI search systems clearer evidence to cite.
Topical Map Clustering Key Takeaways
- Topical clustering groups related keywords, entities, and intents into one site structure.
- SERP overlap is strongest for smaller inventories and live cannibalization checks.
- Semantic embeddings handle large keyword sets with weak or noisy SERP overlap.
- Entity graphs reveal parent-child relationships and missing topic nodes.
- Hybrid workflows combine SERP proof, embeddings, and manual review.
- One primary page should own each intent to reduce cannibalization.
- Validation should check overlap, gaps, entity coverage, and retrieval readiness.
What Is Topical Map Clustering?
Topical map clustering is the process of grouping related keywords, subtopics, and entities into a clear site structure. Instead of publishing disconnected pages, you build topical maps that organize coverage around one main theme. Following the topical mapping process gives that structure its logic, so each page has a job.
The usual model is pillar and cluster architecture. A pillar page covers the broad subject, and supporting pages handle narrower questions, use cases, and comparisons. That is where topic clustering becomes useful, because it turns a loose list of ideas into topic clusters that reinforce one another.
The SEO value is practical. Search engines can crawl the site more cleanly. Keyword cannibalization drops when pages do not compete for the same intent. Topical authority is easier to signal when the coverage feels complete.
The artificial intelligence (AI) value matters just as much. AI-driven search engines, retrieval-augmented generation systems, and large language model assistants rely on meaning, entities, and relationships. Organized topic clusters are easier for those systems to interpret and cite than isolated pages.
Strong topical maps also improve internal linking and navigation. You get natural anchor text, clearer paths between related pages, and better content discovery. Strategic internal linking can improve crawl paths, page discovery, and topic signals, and teams should measure traffic lift against their own baseline rather than assume a fixed uplift (source).
The next steps will show how to cluster topics, assign pages, and check the map for overlap, gaps, and scale before you publish.
Which Clustering Method Should You Use?
The right clustering method depends on how clean your inventory is and how much coverage you need. grouping keywords by intent is the fastest way to read search intent, but it is only one signal. SERP overlap, semantic clustering, and graph logic solve different problems.
Method | Best fit | What it reveals | Main limit |
|---|---|---|---|
SERP overlap | Smaller sites and tight query sets | Shared URLs, cannibalization, competitor gaps | Misses broader meaning |
Semantic embeddings | Large or messy inventories | Meaning, entities, and intent patterns | Needs review |
Entity and graph models | Deep topical authority planning | Relationships, missing nodes, adjacent subjects | More setup |
Hybrid workflow | Most modern topical maps | Better balance of meaning, SERP proof, and structure | Takes more judgment |
SERP overlap is the safest starting point when you want to mirror search intent and spot where Google already groups terms. It also shows cannibalization risk and where competitors cover the topic better than you do.
Semantic clustering, often powered by AI and Large Language Models, works better when the list is large or inconsistent. These systems can group phrases by meaning even when URL overlap is weak. That makes them useful for broader discovery and early topical expansion.
Entity mapping and knowledge graph mapping go deeper. They connect subtopics, expose missing nodes, and support adjacent coverage that SERP-only methods can miss.
Hybrid workflows can be a practical default because they combine SERP evidence, semantic grouping, and manual review (source, source). Mid-sized sites may benefit from embeddings plus review, while larger inventories may need graph logic to preserve coverage and relationships (source, source).
The simplest rule is clear. Smaller sites can often stop at SERP overlap, mid-sized sites benefit from embeddings plus review, and enterprise maps usually need graph logic to stay complete. Whatever you choose, tie the map to internal linking, descriptive cluster labels, and gap-filling content so it supports SEO performance instead of just sorting keywords.
When Should You Use SERP Overlap?
SERP overlap is useful when you need to see how Google is grouping queries right now. If two terms surface nearly the same top URLs, they usually belong in the same cluster, which gives you the clearest read on search intent. It is especially useful for validating an existing SEO structure on a live site, where keyword cannibalization is the real risk and one page needs to own the topic.
SERP overlap can work well for smaller inventories and query sets with stable results, while larger or more volatile sites may need a hybrid workflow that adds semantic review (source, source). That stability makes SERP-based keyword grouping easy to compare side by side, then turn into decisions on format, subtopics, and PAA coverage from what already ranks.
Use it when evidence matters more than guesses:
- Same URLs: shared intent is likely.
- Existing pages: cannibalization becomes visible.
- Stable SERPs: comparisons stay cleaner.
Results vary by site, industry, and implementation, and past performance does not guarantee future results.
When Should You Use Semantic Embeddings?
Semantic embeddings fit larger sets where SERP overlap is too thin to cluster cleanly at scale. They turn phrases into dense vectors, so methods like cosine similarity, K-means, hierarchical clustering, and DBSCAN can group terms by meaning even when live results barely match. That makes them a strong fit for semantic SEO, long-tail keyword sets, synonym-heavy queries, and near-duplicate wording where exact matches are noisy but semantic relevance is still obvious.
Use them when a map is too large for manual SERP review to stay consistent. They also support AI-powered semantic clustering workflows that need cleaner topical grouping for RAG and LLM-based AI search systems. The same semantic relationships help retrieval connect related questions, entities, and intent. SERP methods still matter, but treat them as a validation layer when intent is fuzzy or the live SERP has weak consensus.
When Should You Use Entity Graphs?
Entity graphs also help when your topic has a real hierarchy. A core entity, its sub-entities, attributes, and related ideas need to sit in a visible structure, not a flat keyword pile. That matters in entity SEO because Search Engine Optimization and AI systems both need relationships, not just repeated terms. knowledge graph mapping and entity mapping help you mirror how a subject works in the real world, which is a better fit for topical authority than loose clustering.
Use this approach when extractability matters and you want crawlers and AI citation systems to pull clean answers. It also fits authority builds and complex niches, where you can map core entities from sources like Wikidata, Knowledge Graph APIs, and NLP or Natural Language Processing extractors, then fill the gaps with human review.
- Best fit: Clear parent-child topics
- Best fit: Semantic internal links and structured data
- Best fit: Node-and-edge logic and page weighting
When Is A Hybrid Method Best?
A hybrid method can help when a single signal is incomplete or noisy, because it lets teams compare SERP overlap, semantic similarity, and entity relationships before finalizing clusters (source, source). SERP overlap shows how search engines group pages now. Embeddings catch broad conceptual similarity at scale. Intent and entity extraction add the nuance that keyword-only clustering often misses.
A practical order works best:
- Cluster broadly: use embeddings first to sort large keyword sets fast.
- Validate with live SERPs: check that the groups match real search-result behavior, not just vector math.
- Refine by intent and entities: split clusters that look close but serve different jobs, buyer stages, or named entities.
- Label with Large Language Models: use LLMS after clustering so labels are clear, consistent, and still grounded in the source terms.
- Review manually: catch edge cases, false merges, and missed entities before writers see the map.
That workflow gives you a repeatable path from raw terms to a stable topical map. It also keeps pillar and cluster structure easier to hand off, and it reduces guesswork when AI-assisted drafts still need senior review.
How Do You Run SERP Overlap Clustering?
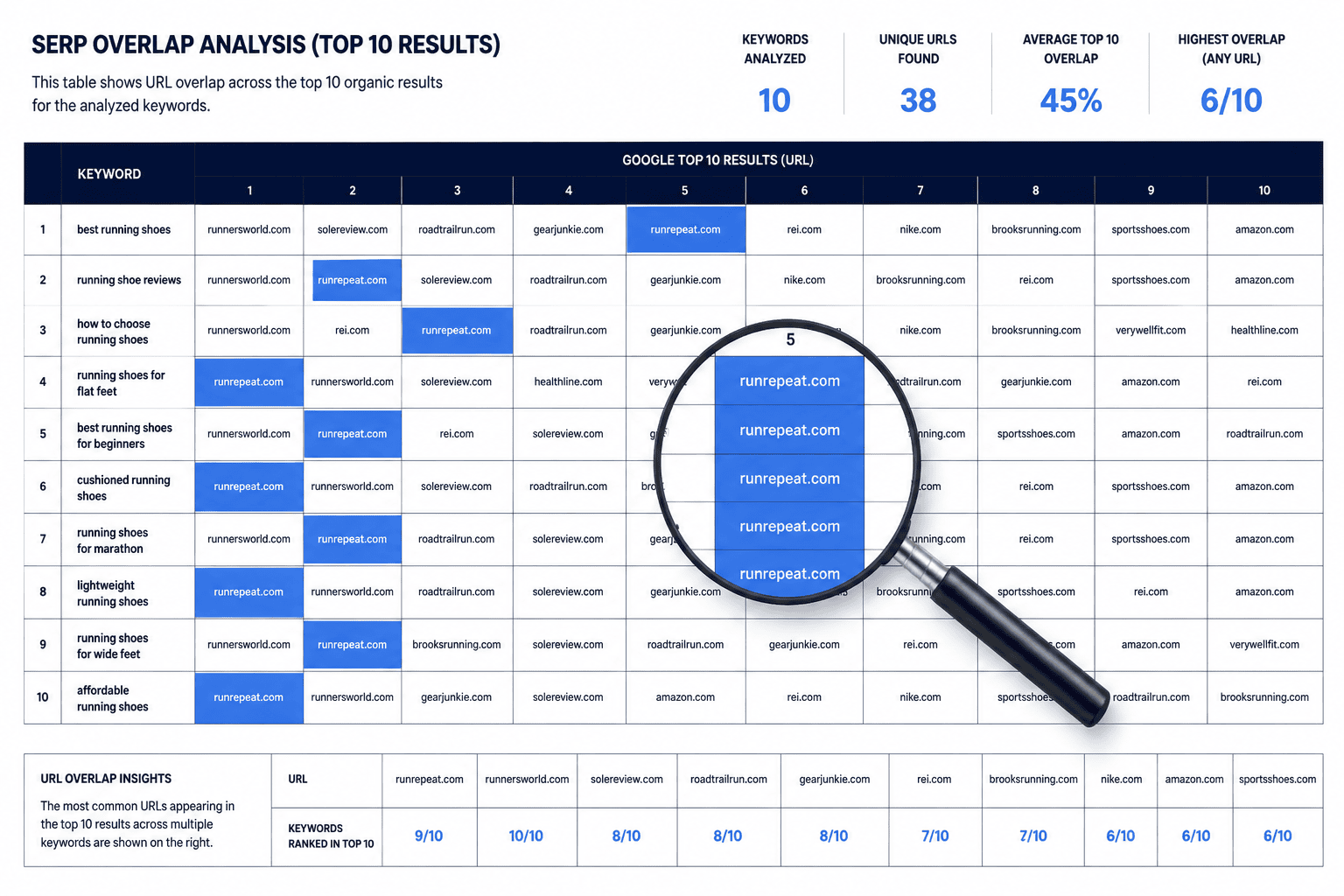
SERP overlap clustering works best when the search results act as the evidence. A clean approach to researching cluster keywords gives you the raw material, and SERP-based keyword grouping turns that material into topic clusters you can publish without stepping on your own pages.
Start with one master sheet and make it the single source of truth. Before any SEO analysis, strip out junk terms, fragments, and irrelevant modifiers so the sheet reflects real queries, not noise. Keep the core fields tight:
- Keyword: the exact query or a close variant
- Monthly volume: the demand signal
- Competition: the market pressure
- Intent: informational, commercial, or transactional
- Topic category: the broader subject bucket
- Priority: the order you plan to work in
From there, build a reproducible SERP table for each keyword. Capture the top 10 organic results with the same rules every time. Use one row per keyword and one column per ranking URL so every query produces a comparable SERP snapshot.
Keyword | URL 1 | URL 2 | URL 3 | URL 4 | URL 5 | URL 6 | URL 7 | URL 8 | URL 9 | URL 10 |
|---|---|---|---|---|---|---|---|---|---|---|
Example query | result URL | result URL | result URL | result URL | result URL | result URL | result URL | result URL | result URL | result URL |
Once the table is built, compare keywords by URL overlap instead of intuition. If two queries share a meaningful share of the same top results, they likely belong to the same intent family. A common working rule is to treat about three overlapping URLs in the top 10 as a starting point, then adjust the threshold based on intent, SERP stability, and cannibalization risk (source, source).
The grouping rules are straightforward:
- High overlap: merge into one cluster
- Weak overlap: keep separate
- Mixed overlap: follow the dominant result pattern
- Different intent signal: split, even when the wording looks close
That last point matters in topic clustering. An exact-match keyword can still trigger a different SERP, and that is your cue to separate it. The final map should reflect the search results, not the phrasing on the page.
Label each cluster with one parent topic that matches the shared intent. Keep close variants as supporting keywords. Use the SERP evidence to infer content format, likely page length, subtopics, and People Also Ask coverage instead of guessing from the keyword list. That is what makes topic clusters more useful for planning and more defensible for AI citation readiness.
The payoff is simple. Better topic clusters reduce cannibalization, help one page map to one intent, and create a cleaner hierarchy for users and AI-driven answer experiences. Save the overlap evidence beside each cluster so the structure is easy to audit, hand off, and defend later.
How Do You Build Semantic Clusters?
A strong cluster build starts with a master keyword sheet, not a loose tool export. That sheet should include the keyword, monthly volume, competition, intent, topic category, and priority so semantic SEO planning, cleanup, and cluster mapping all live in one place. Keep it filterable by silo, content type, and search intent so the same inventory can be sorted several ways without rebuilding the file each time.
Before clustering, the dataset needs a careful cleanup pass. Remove duplicates, split terms with mixed intent, and flag outliers that do not belong in the same topic family. The goal is semantic relevance, not surface similarity. Keyword wording, user intent, and search volume should work together so the final groups match how people actually search and support stronger visibility in AI-generated answers.
A practical workflow uses Natural Language Processing, or NLP, to turn each keyword or query variant into embeddings. Embeddings are numeric representations of meaning. Use one consistent model across the full set so the comparisons stay stable. Embedding models from providers such as OpenAI and Cohere can be used for semantic clustering, and cosine similarity is a standard first pass for comparing vector closeness (source, source). AI-powered semantic clustering is especially useful when search engine results pages do not overlap much, but the language still belongs in the same intent cluster.
The clustering method should match the shape of your inventory. Different datasets call for different tools:
Method | Best fit | Strength | Tradeoff |
|---|---|---|---|
k-means | Fixed cluster counts and even group sizes | Clean, fast, and easy to explain | Needs a chosen cluster count |
DBSCAN | Dense pockets and noise detection | Finds oddballs and tight groups | Sensitive to threshold settings |
Hierarchical clustering | Parent-child topic layers | Good for topical depth and nesting | Can get noisy on large lists |
BERTopic | Large, messy inventories | Transformer-based labels and hierarchy | More setup and tuning |
LDA | Older fallback use cases | Familiar topic modeling structure | Weaker than newer options |
Older latent Dirichlet allocation belongs in the backup lane, not the main scale option. That keeps your workflow aligned with how modern search systems interpret meaning.
After the algorithm assigns groups, use an LLM to label each cluster in a controlled format. Feed it the cluster members, a short intent summary, and seed topic hints. Ask for three outputs only:
- Short cluster name: A concise label that fits the topic
- Primary intent: The main search intent for the group
- Supporting subtopics: Three to five terms that define the cluster's edges
Then export CSV-ready fields such as cluster ID, cluster label, seed keyword, member keywords, intent, and recommended page type so the map is easy to hand off.
Validation is where good topical maps separate from risky ones. Strong clusters stay internally coherent, keep informational and transactional intent apart, and preserve a clear path from broad topic to supporting subtopic. If a cluster is too large, too thin, or semantically muddy, tighten the thresholds or split it by hand. That reduces cannibalization, sharpens internal linking, and gives you cleaner targets for AI citation work.
How Do You Map Entities Into Graphs?
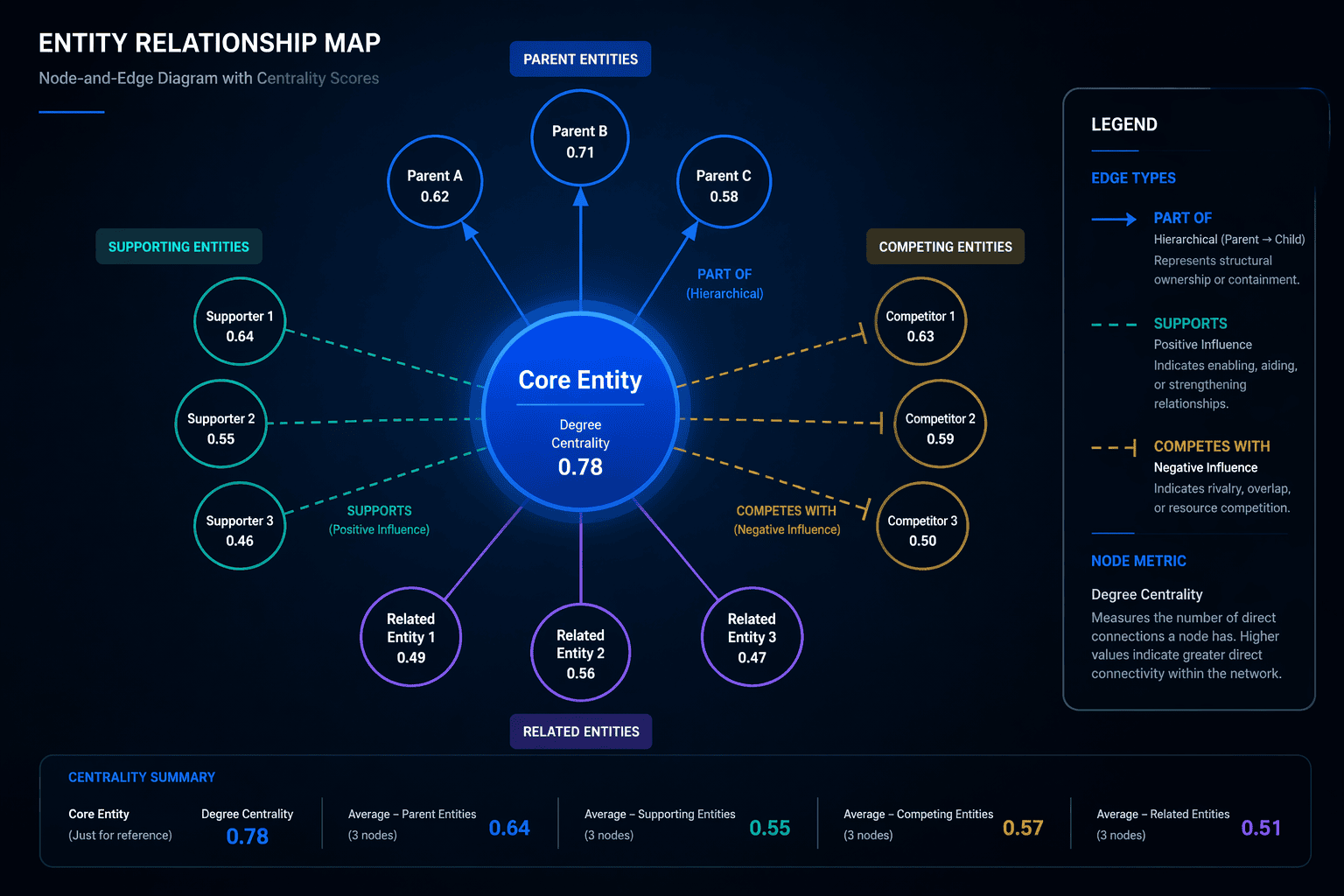
Start with the entities you already have, then clean them into one master list before you touch any graph software. Pull terms from your own pages, support docs, and product content. Then add missed variants from Google Search Console queries, forums, People Also Ask results, competitor crawls, and manual research. That step matters because keyword clusters are often too narrow, while an entity graph shows the full topic space your site needs to own.
External sources make the graph far more useful. Wikidata, the Knowledge Graph API, and NLP extractors like spaCy help you attach canonical names, related entities, and relationship types to each item. A spreadsheet becomes a structured entity map when you can separate core topics from supporting topics and trace how they connect.
From there, build simple node and edge tables so the model stays usable at scale.
Table | What it represents | Common fields |
|---|---|---|
Node table | An entity, URL, or concept | ID, label, type, source, page target |
Edge table | A relationship between two nodes | From, to, relation type, strength, source |
Keep the edge type explicit. Useful relations usually include part of, supports, competes with, and links to. A clean model makes filtering easier, keeps internal linking decisions grounded, and gives you a graph you can actually visualize without turning it into spaghetti.
Community detection gives the graph shape. Louvain is a practical choice because it groups closely connected nodes into topical neighborhoods without forcing you to guess the structure in advance. Those clusters help you spot orphaned entities, decide which ideas belong together on one page, and split topics that deserve their own content.
Centrality scores add another layer of judgment. High-centrality nodes often act as hubs that define topical authority, while peripheral nodes point to gaps, support topics, and long-tail angles that still deserve coverage. Non-lexical relationships matter here too, because graph-based and embedding methods can connect concepts the way users and search engines do.
That usually reveals adjacent opportunities, reduces cannibalization, and strengthens Search Engine Optimization (SEO) performance for AI-driven answer experiences.
The finished graph becomes a planning layer for parent, child, and sibling pages inside the same topical neighborhood. Use it to map internal links, align anchor text, and check whether the site has real depth around the entities that matter most.
How Do You Turn Keywords Into A Final Map?
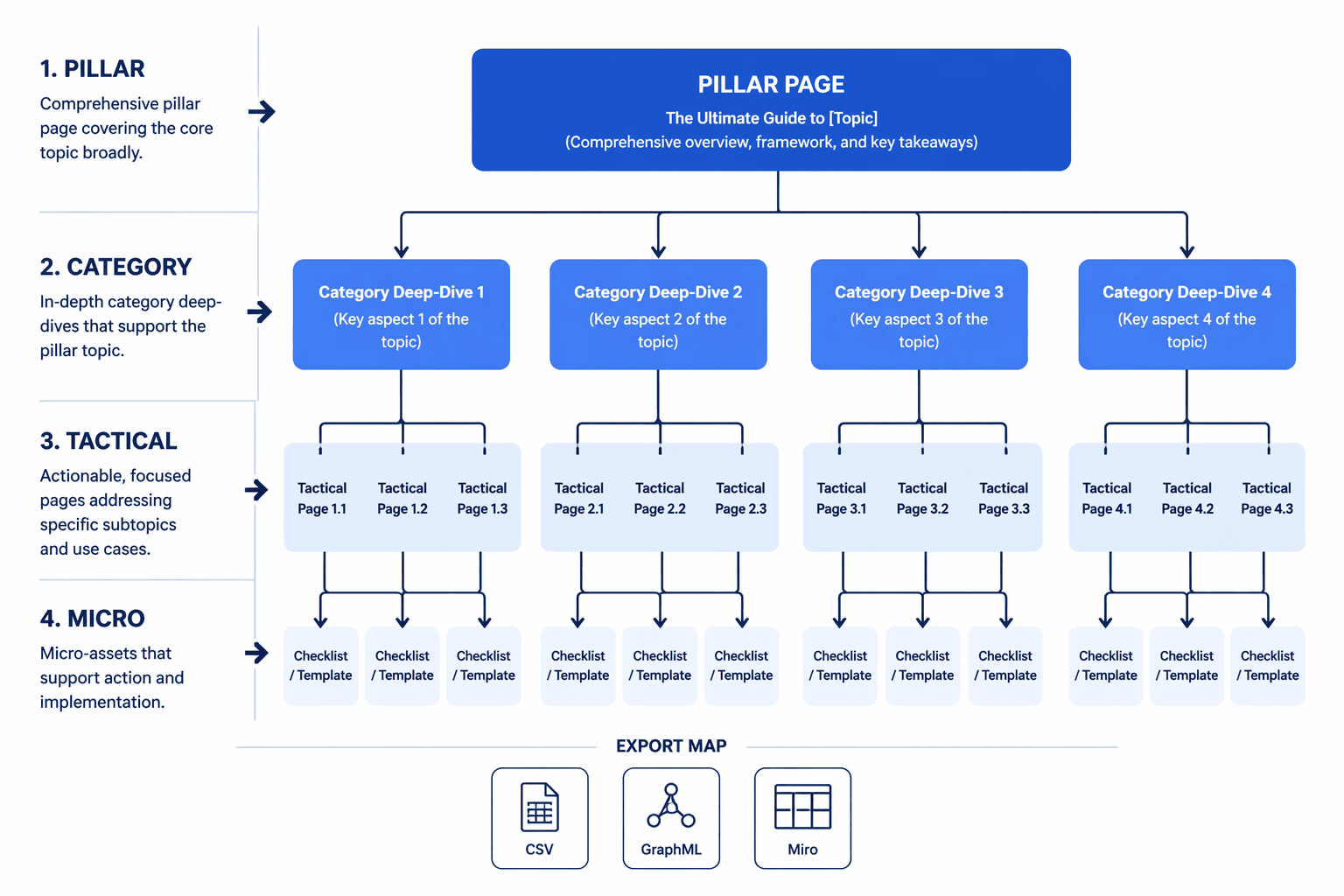
Start by turning each validated cluster into a publishable hierarchy, not a pile of related terms. One core entity becomes the pillar page, and the surrounding topics fan out into a four-tier semantic graph that covers category deep-dives, tactical supporting articles, and micro-assets like checklists, templates, or single-intent tools. That is how topical map clustering stays tied to pages you can actually publish.
The guardrails come before placement. You need one primary page per intent, one canonical URL per topic, and a clear rule for when close variants stay together or split into separate pages. That protects pillar and cluster architecture from cannibalization and keeps near-duplicate terms out of competing cluster pages. For the broader workflow, the pillar and cluster hierarchy shows the process behind the final build.
A simple mapping model makes the roles easy to read:
Tier | Page type | Role in the map |
|---|---|---|
1 | Pillar pages | Own the core entity and set the main theme |
2 | Category deep-dives | Split the subject into major branches |
3 | Cluster pages | Answer narrower, intent-specific searches |
4 | Micro-assets | Capture checklists, templates, and tool-like intent |
Once the structure is set, build internal linking into the map itself. Parent-child links should run from the pillar to the supporting page and back again. Lateral links should connect sibling pages when the relationship is real. Your anchor text and link direction should make the page purpose obvious to users and search engines.
AI-search readiness belongs in the map, not in a separate note. Add short summary sentences, extractable answer blocks, entity relationships, and structured data cues beside each target page. Those notes make topical maps easier for AI engines to cite in generative results and help editors write cleaner first drafts. The same structure also gives your team a better shot at consistent search intent coverage.
Export-ready formats keep the system usable across teams:
- CSV: Fits spreadsheet workflows and fast handoffs
- GraphML: Supports graph-based tooling and relationship analysis
- Miro-style board: Helps stakeholders review the structure visually
Useful columns usually include cluster name, target URL, page type, tier, canonical status, primary entity, supporting entities, and internal link targets. That level of detail makes the map handoff-ready instead of interpretive.
Before publishing, run one validation pass. Confirm every cluster has a single owner, no topic appears twice across tiers, and the hierarchy still matches search intent and site size. For larger sites, keep the map as a living operating system so new products, new models, and new entities can slot in without forcing a rebuild.
How Do You Optimize And Validate The Map?
Start with cannibalization before you publish or refresh anything. Compare each cluster against live SERPs so you can see whether two or more URLs are competing for the same intent. That matters because Google often folds a query family into one preferred page, and a map that looks clean in a spreadsheet can still be muddy in search.
A topic completeness check should go beyond traffic and rankings. It should show whether the cluster covers the full subtopic set, whether core entities and related questions are present, and whether the map has enough semantic density to support AI search visibility. It also helps you spot thin clusters, orphaned subtopics, and gaps in supporting pages before they hurt performance.
The most useful coverage KPIs are easy to repeat across teams:
KPI | What to check | Red flag |
|---|---|---|
Subtopic coverage | Core angles and variants are represented | A major subtopic has no page |
Entity coverage | Key people, products, concepts, and attributes appear | entity SEO signals are thin or missing |
Question coverage | Common questions are answered in the cluster | Support content skips high-intent questions |
Retrieval readiness | Short answers and clean passages exist for citation use | AI-driven search engines would need to parse through filler |
That same discipline matters for extractability. Pages that should earn citations need concise summary sentences, direct answers, clear subheadings, and entity-rich blocks that AI systems can lift without guesswork. If a key point is buried in a long paragraph, move it near the top and strip the filler so Google SGE and similar surfaces can read it cleanly.
Internal linking works best when you test it instead of assuming it is right. Try alternate anchor text, different link placement, and a few hub-to-spoke paths, then compare crawl flow and page ownership signals. The goal is not more links. The goal is clearer intent signals about which page should own the topic and which supporting pages should reinforce it.
A practical validation set keeps the workflow repeatable:
- Flag overlap: More than one page keeps ranking for the same query set.
- Flag gaps: A core subtopic has no supporting page.
- Flag weak pages: The main page lacks a short answer block or structured data.
- Flag drift: The cluster has changed since the last review.
Treat the map as a living asset and review it every quarter. New queries, seasonality shifts, merged pages, retired pages, and content drift all deserve attention. A stale topical map can become less useful as queries, pages, and search intent shift, so teams should review and refresh the map on a fixed schedule instead of relying on an unchanged structure (source, source).
Topical Map Clustering FAQs
These FAQs cover the questions you're likely to ask before using topical map clustering for SEO and AI search. They also show where the method helps, where it can mislead, and what matters most when you choose a workflow.
1. How many clusters should you create?
A practical rule is one cluster for each meaningful subtopic or search intent, with a pillar page and supporting spokes under it. Small sites may only need a few tightly defined clusters, while broad catalogs can need dozens or even 200 to 300 articles across several topic layers before the topical map feels complete. Use your content inventory and coverage KPIs to set the final count, and stop when new clusters no longer close gaps, reduce cannibalization, or add distinct value to topical authority through topical map clustering.
2. What seed keywords should you start with?
Start with your core entities, because they define the page and anchor the rest of the topical map. Add high-intent modifiers such as comparison, best, how to, pricing, and use-case terms, then mine Google Search Console queries for the language your site already surfaces. A quick competitor crawl helps you spot missing entities, and a broad seed set makes it easier to build a clean hierarchy with definition, use case, advanced guide, and FAQ pages.
3. How do you set cluster overlap thresholds?
A practical default is to cluster two queries when they share about 3 of the top 10 URLs in the SERP. Tighten that threshold when the terms are commercially close, target the same page type, or show cannibalization risk, and loosen it when intent is adjacent but the results still split. Treat overlap as a signal, not a rule, and check whether the ranking pages also match on format, subtopics, and PAA questions before you split or merge. If overlap is low but one query is clearly a subtopic, keep it in the cluster only when one stronger page is better than several thin ones.
4. How deep should a topical map go?
Most topical maps work best at 3 to 4 tiers: a pillar page, category deep-dives, supporting tactical pages, and a fourth layer only when the topic really earns it. Broad, strategic pillars usually need more branching, while narrower topics often stop at Tier 3 without losing coverage. Use a fourth tier only for distinct assets like checklists, templates, or single-intent tools, and treat four clicks deep as a practical ceiling unless the site is large enough to maintain the extra structure.
Sources
- source: https://cited.so/blog/topical-authority-map-creation
- source: https://floyi.com/blog/automated-topical-mapping/
- source: https://topicalmap.ai/blog/auto/keyword-clustering-workflow-for-content-strategists
- source: https://www.scribd.com/document/961337574/Standard-Operating-Procedure-SOP-for-Topical-Map-Creation-docx
- source: https://learn.microsoft.com/en-us/azure/azure-maps/clustering-point-data-web-sdk